强化学习在人才推荐中的应用
2020年5月30日
在人工智能的发展历程中,搜索和推荐一直占着非常重要的地位。在搜索方面,Learning to rank(LTR)一直是热门研究领域,但是Learning to rank常常将搜索排序作为一个静态问题,招聘方在当前页面的点击很少被用来优化下一页面的排序。
推荐引擎也有着同样的问题,大部分推荐都是基于item to item的静态推荐,只有少部分推荐引擎会根据招聘方的反馈动态调整推荐结果,从而达到更加个性化的推荐。
传统推荐系统
传统的推荐系统通过两个范例进行建模,即协作过滤和基于内容的系统。 在基于协作过滤的方法中,“用户与项目的交互矩阵”记录了用户过去与项目的交互。而基于协作过滤器的方法的基本概念是基于相似度来检测相似用户及其兴趣。
协作过滤算法可以基于以下方法构建:基于内存和基于模型。
基于内存: 把新用户标识为最相似的用户,并推荐其最喜欢的内容。由于无法量化误差,基于内存的方法因此没有方差或偏差的概念。在基于模型的方法中,在用户-项目交互矩阵的顶部构建了生成模型,然后将该模型用于预测新用户,从而观察到模型偏差和方差。
- 基于内容: 除了用户-项目交互之外,还考虑了用户信息和首选项,以及与内容有关的其他详细信息,如受欢迎程度,描述或购买历史记录等。用户功能和内容特征是馈入模型,该模型的工作方式类似于具有错误优化功能的传统机器学习模型。由于此模型包含与内容有关的更多描述性信息,因此与其他建模方法相比,它倾向于具有较高的偏差,但方差最低。
强化学习
到目前为止,您可能已经理解,推荐的目标是向合适的用户推荐合适的内容,以便获得更好的内容评论。通过在增强学习模型中使用Markov属性,可以很好地构建推荐系统。强化学习问题可以以内容为状态,动作为要推荐的下一个最佳内容,奖励为用户满意度/转换或评论来表述。训练模型的每个内容都可以转换为向量嵌入,这使我们认识到动作空间不是离散的,而是连续的。从内容准备的嵌入内容可能会根据要求而有所不同,并且完全取决于主题的专业知识。自然语言理解本身就是一个巨大的研究领域,涉及从内容中提取信息的多种技术。该概念也被称为“最大化保留信息”。
根据Markov属性,推荐系统问题可以解释为给用户的新推荐-独立于先前的推荐。在这种情况下,我们发现使用强化学习模型的另一个优势,该模型说明了勘探与开发之间的平衡。该算法不仅会向用户建议他们可能会找到的最有用的内容,而且还会建议一些随机内容,从而引起新的兴趣。强化学习模型还将不断学习,这意味着,当用户的兴趣发生变化时,推荐内容也会发生变化,从而使模型变得更加健壮。
强化学习在人岗匹配的运用
今天就讨论一下小析智能是如何采用增强学习的方法对推荐和搜索问题进行优化的。 首先,我们将推荐的过程看做一个Markov Decision Process,那么需要定义如下几个元素:
- 状态空间S:从s_1到s_n,定义为招聘方的浏览候选人的历史。
- 动作空间A:我们向招聘方推荐的候选人列表。
- 招聘方反馈R:招聘方看到我们的推荐的结果a后,点击或邀约面试。
- 转换概率P:用p(s_t+1|s_t, a_t)表示招聘方状态转换。
- 折扣因子γ:表示不同时间回报的折扣。
我们将招聘方点击候选人的顺序提取出来,采用Word2Vec的方式学习他们的特征。然后在模型中直接采用特征进行学习。
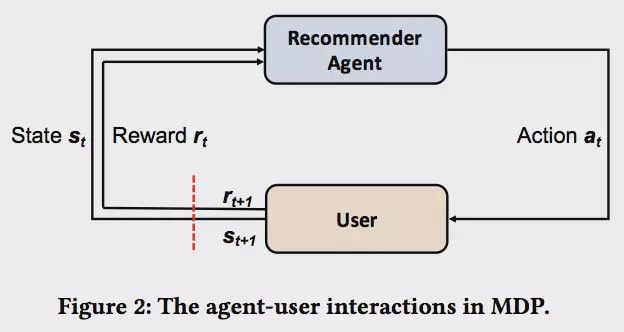
上图为学习框架,推荐系统不断地做出推荐a_t,招聘方根据a_t产生反馈r_t,进入状态s_t+1,推荐系统再根据反馈调整参数,进行新的推荐。 推荐系统的训练采用了Actor-Critic方法。Actor部分是一个深度神经网络,根据当前的状态s_t,通过神经网络产生一组权重向量w_t,然后选取依次选取商品,使得每一个商品的特征向量与权重向量內积最大,就是一个打分的过程。具体的算法可以参加下面的伪代码。

我们用Critic去评估Actor生成的推荐列表。在真实的推荐系统当中,由于状态空间和动作空间是非常大的,对于每一个(s,a)组合,计算Q(s,a)变得不现实。所以这时候我们就采用另一个深度神经网络,将状态的特征向量和新的推荐候选人的特征向量作为输入,生成对于Q函数的估计。 以下是Actor网络和Critic网络的大致结构:
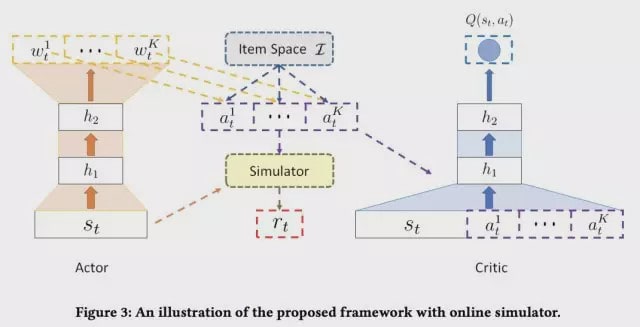
模拟器受到collaborative filtering方法的启发,一方面看过相似候选人的招聘方所处的状态是相似的,我们可以用两个状态s的cosine similarity来衡量状态相似性;另一方面,对比两个状态下推荐a的cosine similarity来衡量推荐结果相似性。最后用参数α将两部分相似性合并起来,推算当前状态获得奖励r和记忆中从前的情况下奖励相似概率。
非常感谢您的阅读!您也可以试着使用强化学习开始构建自己的推荐系统。