深度学习 - 岗位理解新方式
2020年2月27日
小析智能的人岗匹配一个非常重要的流程是将用户想要推荐的岗位名称进行标准化,然后对海量简历完成初步筛选。小析内部有一个完整标准化岗位的知识图谱,如何将用户输入的五花八门的岗位标准化分类到对应的标准化岗位是一个非常重要的问题,直接影响到人岗匹配的初筛结果。
Java程序员,java工程师,java软件开发,表达出来的都是java的标准化岗位。在这种情况下,如果招聘人员搜索的是java软件开发,其希望匹配的对象应该包括了以上三类,而不是仅仅进行java软件开发的简历的匹配。此文中,我们将介绍一下小析智能在岗位标准化的研究进展。
深度研究
在小析智能,我们不断努力着更新完善我们的人工智能技术。因此,我们的研发人员每个星期五有固定半天的自发兴趣研究时间来阅读最新的机器学习论文和研究成果,并评估在我们的产品中带来改善的可能性。特别是针对用户提出的建议和问题,我们会尝试脱离现有的系统,尝试使用更合适的技术来解决客户的问题。
某天,小析智能研究员小张阅读到了一篇2019ACL会议的一篇论文,里面提到了使用孪生时间循环神经网络来计算两个文本实体的相似度。并认为该方法说不定适用与我们的搜索岗位标注化的问题。能对我们目前使用浅学习加集成模型(boosting)带来改善。于是我们便启动了我们的效果对比流程。所谓效果流程,就是将新旧版本算法在一个较大的数据集中运行,然后让专家对两个版本的效果进行评估标注,如果新版本统计性显著比旧的版本后,在考虑后各种场外因素(如运行时间,代码维护成本等)后会将算法进行迭代。最后统计得出,在890个标准化岗位里,我们的岗位标准化测试集准确率从96.2%提高到了98.4%, 特别是对于一些小析较罕见的行业类别(光电子行业,服务行业)准确率有了显著提高,保持了我们人岗匹配系统在行业的领先优势。
岗位标准化
很多岗位名称有多种不同的表达方式,例如上面提到的java软件开发的例子。同理,算法岗可能也叫机器学习工程师,数据科学家。这个例子比较极端,岗位名称中基本没有出现相同的字,但基本意味着同样的意思。这样使得传统的词袋模型没法对其相似度进行计算,因为相似度都是0。同样,岗位的叫法也取决于公司的文化,行业,甚至招聘经理的书写习惯。
比较常见的特征提取是对中文词语进行分割,然后以序列方式表示。例如高级机器学习工程师可以表达为‘高级’,’机器学习’,’工程师’。而资深数据科学专家可以表达为‘资深’,’数据科学’,’专家’。根据传统计算机的理解方式,其会计算两个序列出现词的相似度和顺序,在这种情况下,我们一般的机器学习算法会判定其相似度非常低。还有一个情况,如果招聘经历打错了字变成机器学习供程师,则会严重影响匹配的准确度。这样明显会大大影响用户体验,我们需要更聪明的匹配方法。
再看一个例子,有客户直接使用招聘网站发布的岗位名称进行招聘,如大数据工程师(四大银行,薪资优厚),如果算法无法正确提取真正表明岗位的部分进行核心分析,会闹出预测成金融岗位的笑话。在此插播一个小析对此情况的匹配结果,我们的人岗匹配系统在职能标准化时专注于对大数据工程师这个岗位关键词进行分析,不会被其他词语影响。
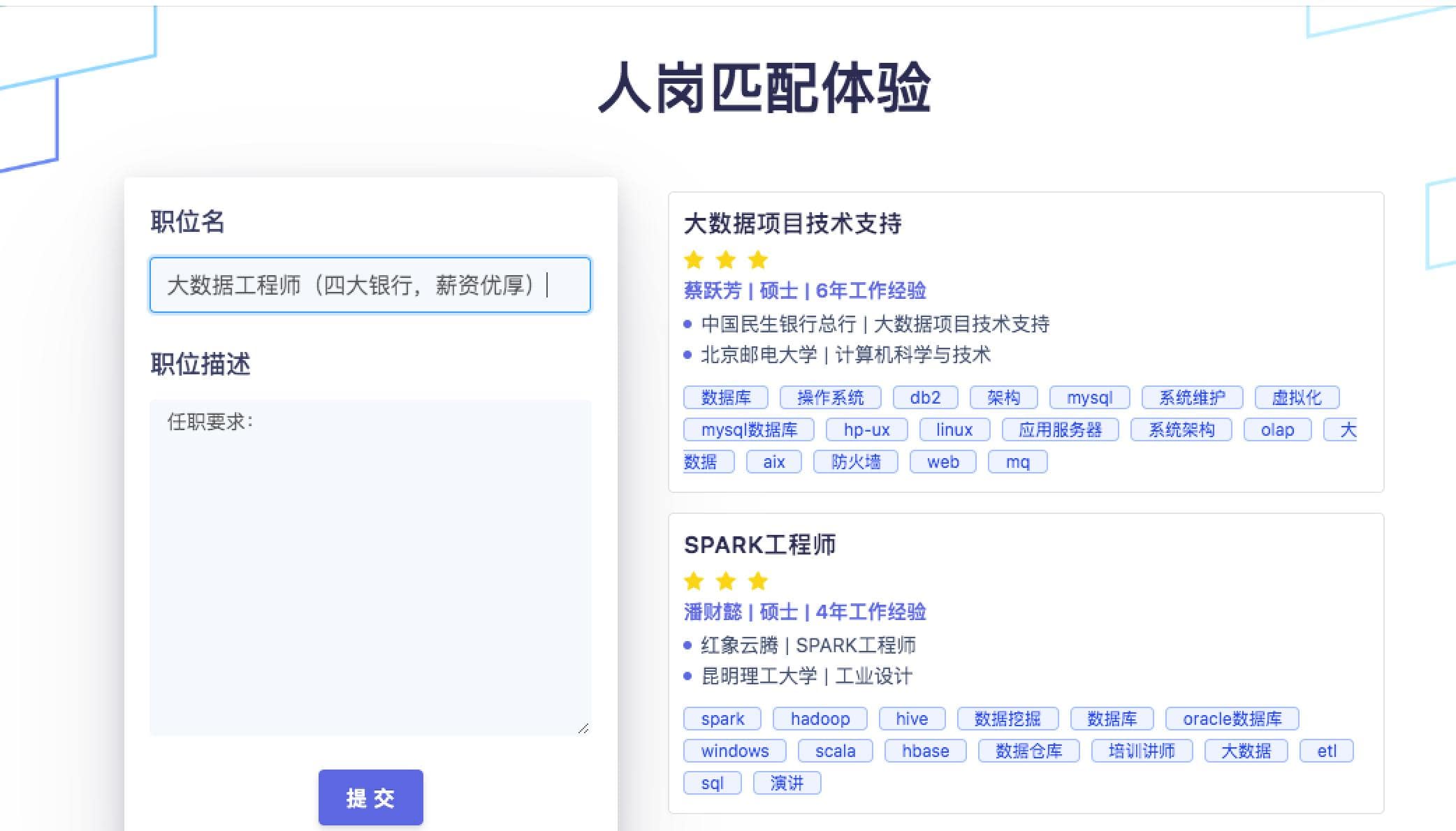
综上,一个优秀的匹配方法需要有如下特点,
- 应该能够理解同义词
- 能够忽略和岗位无关的词语
- 能够处理拼写错误和不同表达方式
岗位名称深度表示
为了更好地对输入的岗位名称有更深度的理解,和小析简历解析一样,我们引入了深度学习技术。深度学习的优势是不需要用手动对输入进行特征提取,如分词,停顿词处理等。并且针对每个字或者每个序列有一个高维度的向量表达。这样可以更好地比较两串输入的相似度。
对于岗位标准化的问题,我们的目标是相同的岗位有相似的向量表达,而不同的岗位有相距甚远的向量表达。在此,我们收集了上千万的岗位对数据,并有对应两个岗位关系的标签,如果两者相同,标签为1,否则为0。然后使用了双向LSTM(长短记忆模型)作为embedding层,并加入了attention机制使权重集中在重要的地方对数据进行向量化处理。最后将两个输入的隐藏层输出作为孪生神经网络的输入,得到最终相似度的能量函数。
下图是简化的网络机构描述:
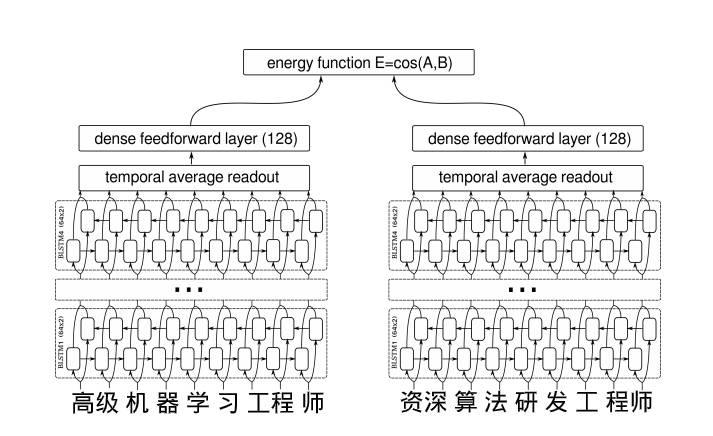
引入深度学习表示让小析智能的岗位标准化有了显著的提高。
非常感谢大家花时间阅读本文。最后祝大家新春快乐,新的一年身体健康,心想事成~