深度学习 - 简历解析的新浪潮
2019年4月7日

小析智能一直倡导用机器学习来更快,更轻松地连接简历与职位。该技术最基本组成部分是我们的简历解析模型,目标是从非结构化文本中提取最重要的信息,从而储存至用户数据库,再进行管理,搜索和分析。最近,我们通过将炙手可热的深度学习应用于现有简历解析模型,对多个字段的准确率有了大幅度的提高。自2018年以来,深度学习逐渐变成我们数据科学家团队的主要研究方向。在小析智能新一代的简历解析中(v2.0.0),传统的机器学习模型被深度学习神经网络模型所取代。新模型在不同模块和字段提取上取得了显着的进步,减少了对手动特征工程的需求的同时大幅提高了字段准确度和细粒度。
深度学习对序列标记的优势
准确的序列标记是简历解析的基础,如对简历不同模块的划分,不同经历之前的切割等都需要准确的序列标记。早在深度学习革命之前,隐马尔可夫模型(HMM)和条件随机场(CRF)就是这个问题的最佳模型。两种方法都采用一系列输入实例并学习预测最佳标签序列。
HMM和CRF最着名的缺点之一是缺乏语义理解能力。例如,他们无法判断“苹果”和“橘子”的关系比“苹果”和“铅笔”要相近。这直接导致他们非常难在未见过的字词中有良好表现。由于模型经常在有限数量的带注释文档上进行训练,因此不同领域上的性能可能会有很大差异,具体取决于领域是否被训练数据集覆盖。例如,我们的简历解析训练集中可能有大量互联网行业或金融行业的数据,但是如果需要解析的简历是训练数据中不多的行业,预测效果则可能会没这么准确。
HMM和CRF的另一个缺点是他们都基于马尔可夫链的模型。由于应用了马尔可夫假设,模型在处理较长的顺序依赖性方面存在困难。例如:经常忽略长于3步或更大的输入序列的依赖性。相比之下,RNN(递归神经网络)模型旨在捕获局部依赖性并发现更长的模式。更长时间的记忆能够使我们的简历解析算法更加精准,例如我们知道了第一行出现了一个姓名,在简历中段出现了另外一个类似姓名的公司名,我们就能判断这个不是候选人的名字,而是别的实体。
词向量的引入
有机器学习背景的读者大概能想到词向量的应用。什么是词向量?词向量是词语的数字形式表示,并且是词语的语义更丰富的表达方式。相近意思的词语会有相似的词向量。这样算法就能判断出来“苹果”和“橘子”的意思要比“苹果”和“铅笔”更相近。
尽管可以(包括我们在深度学习时代之前的工作)尝试使用词向量作为CRF模型的特征,但神经网络模型直接在词向量上进行直接操作,并且模型有更好的泛化能力。即它们可以识别新的没有出现在训练数据中的公司名称,岗位名称等重要信息。
特征工程的引入
传统模型开发的很大一部分是找到一组高质量的特征。过程中需要机器学习工程师大量的时间去手工提取和调整特征。例如,添加字体信息(字号,是否加粗等)可以在很大程度上提高简历解析性能。在将CV解析服务扩展到新语言时,对手工特征的依赖性构成了一个非常困难的问题。相比之下,深度神经网络已经显示出强大迁移学习能力,能够从大量无标注数据中学习出语言的特征,不依赖于人工提取。这也为我们改善英文简历解析不用花费双倍的时间。
小析智能的深度学习模型
在使用不同的RNN单元后,我们选择比较强大的LSTM单元来构建我们的序列标记网络。模型的输入是一系列标记,它们的架构如下:它从一个one-hot编码开始,在其词向量中查找单词,将单词转换为词向量并将其输入双向LSTM(这个实际上是两个独立的神经网络层,一个从头到尾提供数据,一个从头到尾提供数据)。双向LSTM每个步骤生成一个表示向量,并且合并两个向量以创建更好的上下文表示向量。在一个或多个双向LSTM层之后,使用softmax层计算每个输入实体的可能类的概率。为了让预测的标签序列有更好的一致性,我们使用softmax概率与来自线性CRF层的转移概率相结合。换句话说,CRF层在预测单词标签时会考虑周围单词的标签而不是直接预测每个单词本身的标签。
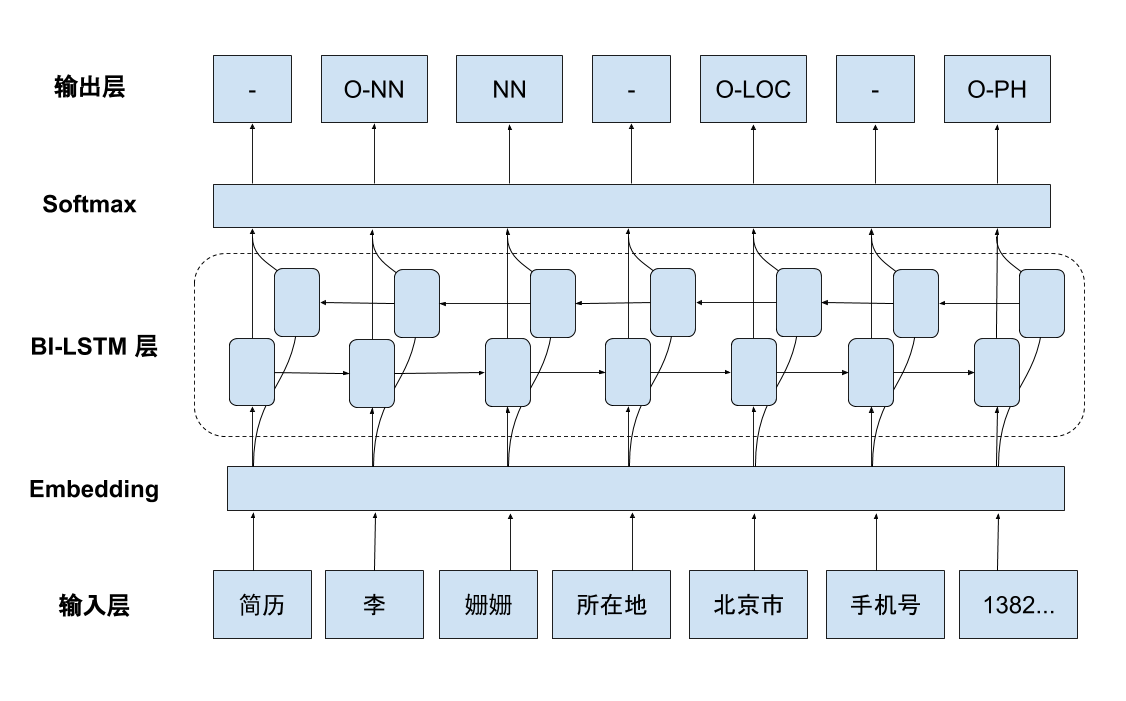
该模型设计非常灵活,能够用于不同的序列标记问题。例如。当工作实体是短语,即句子或行时,模型能够生成短语表示以馈送到网络并标记短语序列。在这种情况下,应用卷积神经网络(CNN)将所有的词向量组合成一个。词向量通常在非常大的语料库上训练,并且仅训练较小的一部分不常出现的单词。然而,对于形态丰富的语言和复合语言,未知单词的出现会显著增加,并且可能对模型的性能产生很大影响。对于这种情况,对于中文语言,我们会直接运用字向量。就像人类学习语言,每个词会由不同的字组成,每个字向量的总和可以用作表达未出现的词向量。这种方式消除了未知词汇,并对这些语言模型带来了实质性的改进。像人脑需要经验来学习和推导信息一样,深度神经网络模型可能包含数百到数十亿个参数,这些都需要从训练数据中逐步学习。训练过程包括确定模型复杂度(层数,隐藏单元的大小等),以及在给定模型复杂性的情况下找到最佳模型参数集(权重,偏差)。我们的研发团队已经构建了一个工具集来提取和处理数据,训练和评估模型,并将最佳模型集成回解析产品。这使我们能轻松地对新数据集和样本进行快速的实验,并加速推出新的更好的模型。
深度学习结果
深度学习模型大大提高了模型的准确性,轻松超越了传统机器学习模型的性能。对于中文简历,新的深度学习模型以及旧的基于机器学习的模型的比较。深度学习模型显示教育领域相对改善10%~20%,工作经历领域占15%~35%。将深度学习应用于其他语言时,也会出现相同的趋势
通过这个结果,我们再次证明深度学习是一套非常强大的NLP问题技术。对于小析智能简历解析,这是一扇新门已经打开。关于如何进一步改进我们的解析模型,我们有很多想法及探索方向。更多的研究工作和令人兴奋的改进正在进行中,敬请关注!