利用图嵌入提升人岗匹配的效果
2022年7月13日

随着新时代的发展和科技的进步,信息技术成为了人力资源领域必不可少的应用工具,原本需耗费大量人力、物力、时间的海量数据处理工作,逐渐变的低成本、精简和高效,人力资源领域数字化、智能化正在得以日新月异的蓬勃发展。为了提升小析智能在人岗匹配及知识图谱产品的效果,我们不断更新迭代完善效能,与时俱进的将图嵌入(Graph Embedding)应用到模型中。通过以下这篇文章,我们将简要介绍图嵌入的理论知识及实践应用。
首先,我们用一句话简单定义知识图谱(Knowledge Graph),就是指用图片的形式存储和表达知识,把不同种类的信息连结在一起所形成的关系网络。而在人力资源领域中,知识图谱发挥着重要的作用,可以用于展示求职者、公司、职位、专业、技能等不同实体之间所存在的多种类型的关系网。受益于知识图谱在各个领域的广泛应用,面向知识图谱的图嵌入学习也得到越来越多的研究和关注。今天,我们重点讲解一下图嵌入(Graph Embedding)。通过图嵌入技术,可以把前述实体嵌入到低维的向量空间,直接比较彼此之间的相似性,从而大幅度提高简历和岗位的匹配效果。对类型较多且各类型数量较大的节点而言,效果更为显著。
关于自然语言处理(NLP),需要首先自然语言映射到欧几里德空间,进而再应用到数学模型的建立中。Embedding可以将自然语言转化为向量,通过Google推出的Word2Vec模型,将语义相近的词映射到向量空间中相近的位置,之后Google提出的BERT可以考虑到相同词在不同位置有不同含义等信息,利用这个新的语言模型同时加上Embedding作为深度学习模型的隐藏层,极大提升了模型在问答、文本情感分析等多个语言任务的表现。
在数学上,Embedding表示映射F: X -> Y,即表示一个函数,其中该函数是一一对应的(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然),并且保持空间同构性 (即如果在X空间是近邻的,则被映射到Y空间也是近邻的)。Embedding技术被应用在了多种业务场景中:
基于内存: 把新用户标识为最相似的用户,并推荐其最喜欢的内容。由于无法量化误差,基于内存的方法因此没有方差或偏差的概念。在基于模型的方法中,在用户-项目交互矩阵的顶部构建了生成模型,然后将该模型用于预测新用户,从而观察到模型偏差和方差。
- 基于内容: 除了用户-项目交互之外,还考虑了用户信息和首选项,以及与内容有关的其他详细信息,如受欢迎程度,描述或购买历史记录等。用户功能和内容特征是馈入模型,该模型的工作方式类似于具有错误优化功能的传统机器学习模型。由于此模型包含与内容有关的更多描述性信息,因此与其他建模方法相比,它倾向于具有较高的偏差,但方差最低。
关于如何生成Graph Embedding及其原理
随着Graph Embedding的使用愈发频繁,人们开发了许多embedding的计算方法,接下来小析将介绍几种商业上较为常用的方法:
1. DeepWalk
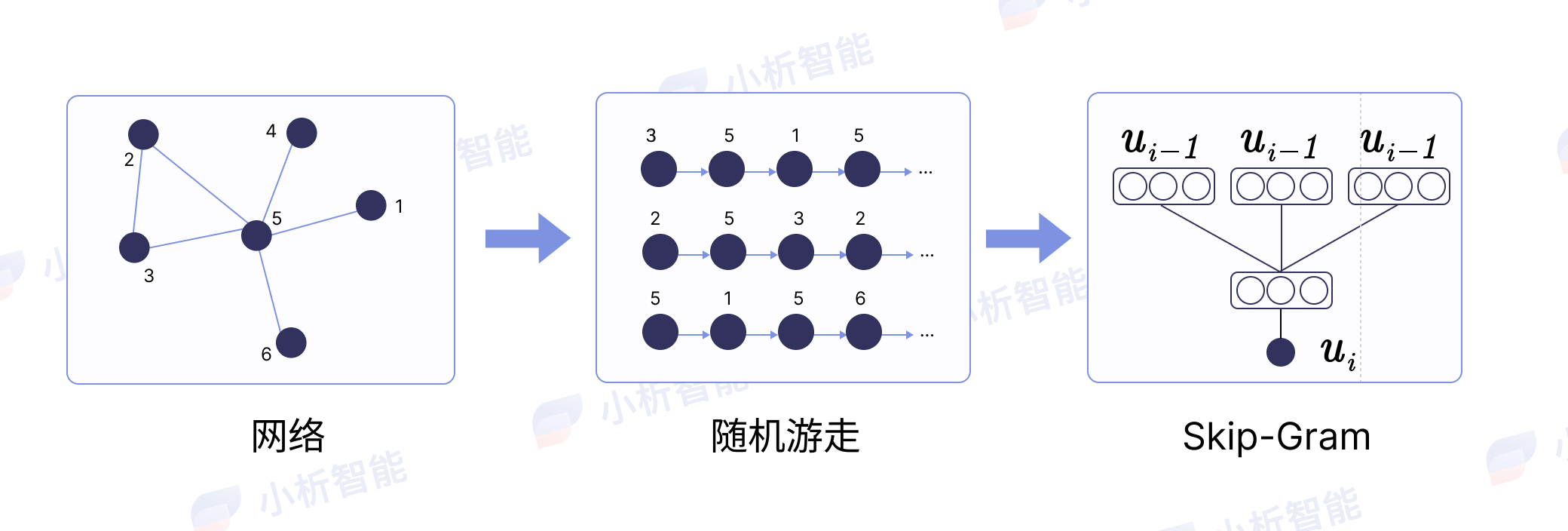
DeepWalk 1 源自KDD2014年的一篇文章,我们常用的word2vec的算法思路是通过词的共现关系,利用skip-gram和COBW的方式将词映射到低维向量,而DeepWalk则是利用了word2vec的思路生成embedding的一种模型(skip-gram)。对于已经建立的Graph来说,每个节点都可以是不同的实体且实体间可以存在不同的关系,从图上的一个节点开始随机游走(random walk),如果节点之间有权重则可以根据权重的不同进行walk来生成类似文本的序列数据,实体id作为一个个词通过skip-gram训练得到词向量。
如下图所示,DeepWalk的大体思路是:根据网络节点随机游走 -> 生成一定长度的随机序列 -> 利用skip-gram进行模型训练。
2. LINE
源于文章2 提出来的一种算法,LINE(Large-scale Information Network Embedding)定义了两种可以计算节点相似度的方法:分别是一阶相似度(First-order proximity)和二阶相似度(Second-order proximity)。
- 一阶相似度
一阶相似度是指两个点之间的相似度,当两个点相连的边权重越大,意味着这两个点越相似。假设两个节点之间没有连接,则一阶相似度为0;但需要注意的是,一阶相似度仅适用于无向图,不适用于有向图。下列是对每个无向边,定义顶点和的联合概率分布计算公式:
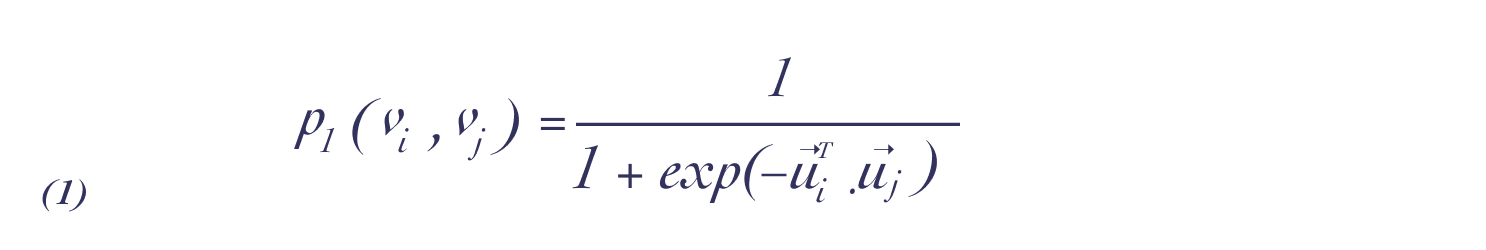
下一阶相似度的目标函数可定义为:
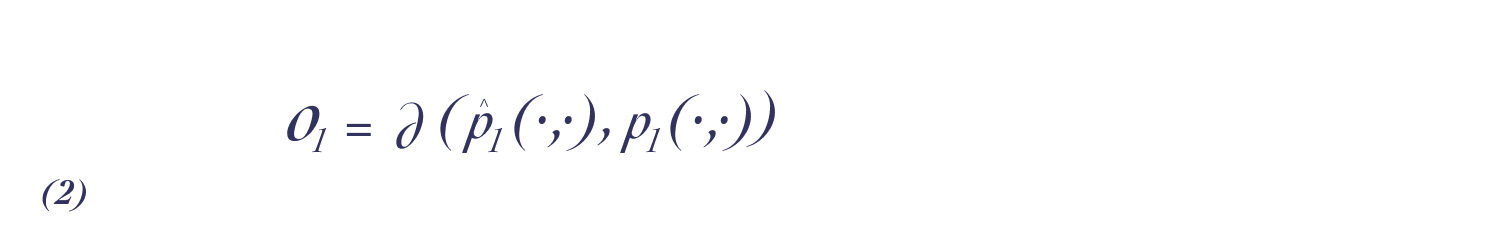
这样可以使经验分布和概率分布尽可能的相近,然后可以通过KL 散度来计算公式(2)。KL散度计算公式是从熵计算公式简易变形而来,在原有概率分布p上,加入近似概率分布q,比较两个概率分布的相似性:
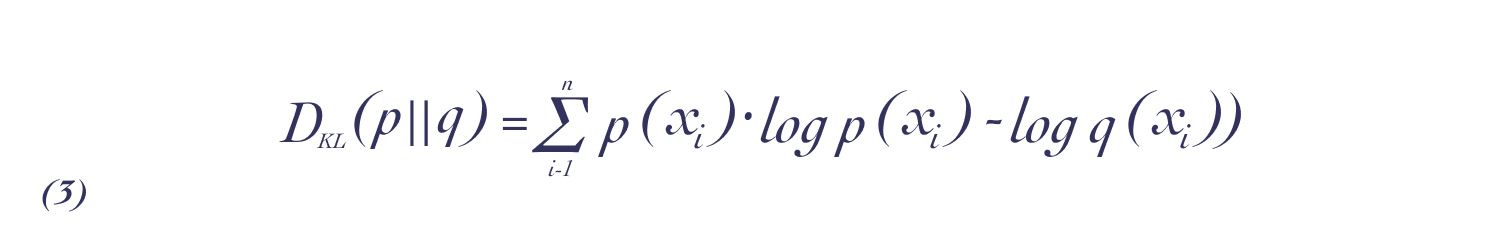
带入KL散度公式后,我们得到了以下公式,其中C为一个常数:
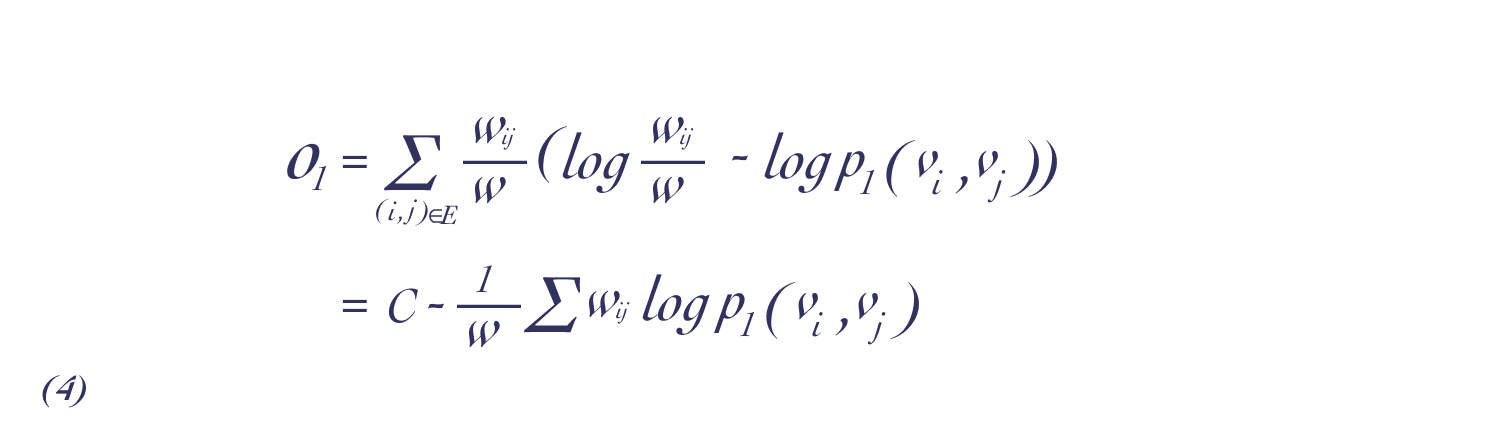
- 二阶相似度
二阶相似性是指两个点临近网络结构之间的相似性。假设两个点与其他顶点共享相邻顶点属于彼此相似(无向或有向均可),一个向量和分别表示顶点本身与其他顶点之间的特定关联关系。对于每个有向边,先来定义由顶点生成关联关系的概率:
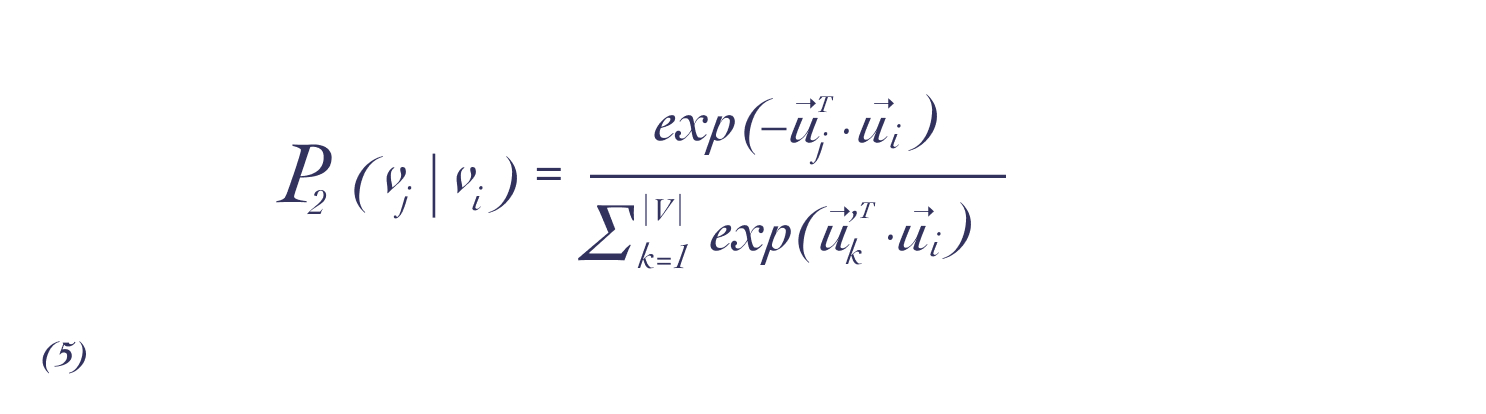
公式(5)是一个条件分布,目标是拟合与顶点经验分布,以最小化以下目标函数:
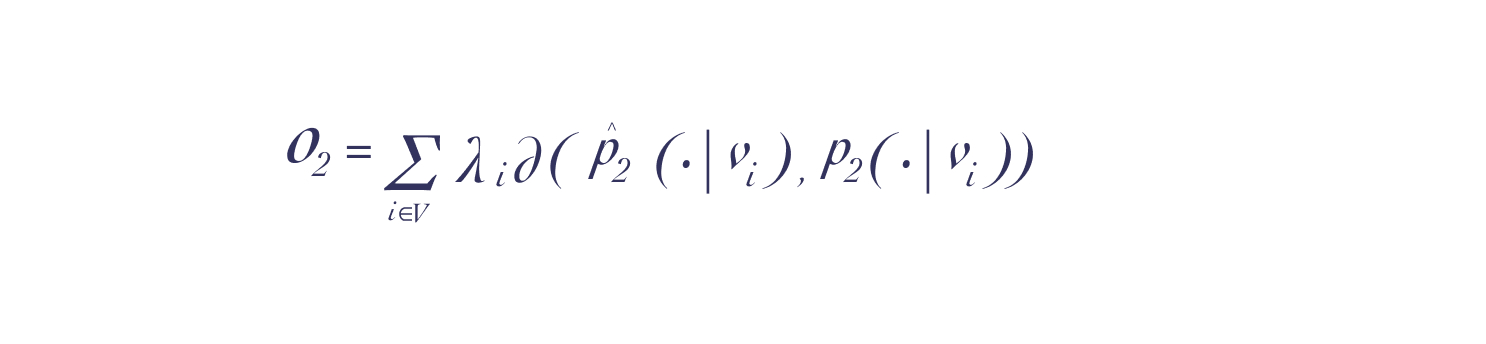
这里我们利用KL散度同一阶相似性的推导,可以得到二阶相似性的计算公式(去掉常数项)为:
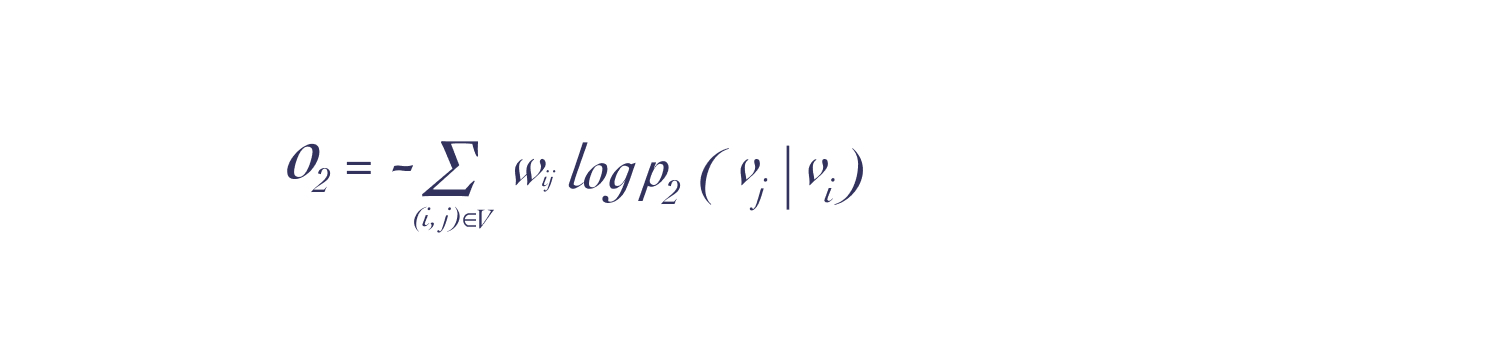
具体应用时,我们可以将一阶和二阶得出的embedding进行拼接,进而可以得到更多的语义信息。
3. Node2vec
Node2vec3在DeepWalk基础上创新改进了随机游走的策略,DeepWalk根据边的权重随机游走,而Node2vec考虑了整体和局部的关系,并增加了权重调整参数,具有更高的适应性。
除了以上所述生成embedding的常用方法,理论和实践中还有很多其他方法,比如SDNE4、Struc2vec、EGES(阿里推荐使用)、Starspace5(Facebook使用)等。
关于图嵌入对人岗匹配的改变
在人力资本行业,简历和职位介绍是最重要的两个要素,人力资本行业一直非常重视二者的有效合理匹配,因此图嵌入的使用大大促进了人力资本行业的发展。
- 原始文本处理
有效、合理、准确的人岗匹配,需要综合考虑包括但不限于职能、行业、技能、专业等多维度要素。首先,可以利用深度学习模型提取简历、职位介绍中的文本特征(即本文所称“实体”),然后便可以将简历和职位介绍进行匹配,对于非格式文本(即个性化简历)而言,匹配结果可能为能够完全匹配或者无法完全匹配,对于无法完全匹配的情况,我们可以计算二者的相似度,但仍可能存在部分词的语义相似度无法被完全诠释的情形。例如:
- 简历的特征:技能实体对应Python,职能实体对应Python开发工程师、专业实体对应计算机专业;
- 职位介绍的特征:技能实体对应NLP,职能实体对应算法工程师、专业实体对应计算机。
从词的表面难以区分两个词的语义相似度。此时可以使用embedding,把不同实体嵌入到同一低维的向量空间,通过数学公式计算实体之间的距离,据此判断相似性。
- Embedding形成步骤
步骤一:如图 1 所示,首先通过简历、职位介绍中不同实体之间的共现关系作为跳转,从而在简历中进行实体跳转,不同的实体之间构成了网络。不同的实体可以视为不同的节点,而实线就是节点之间的边,也可称为关系。
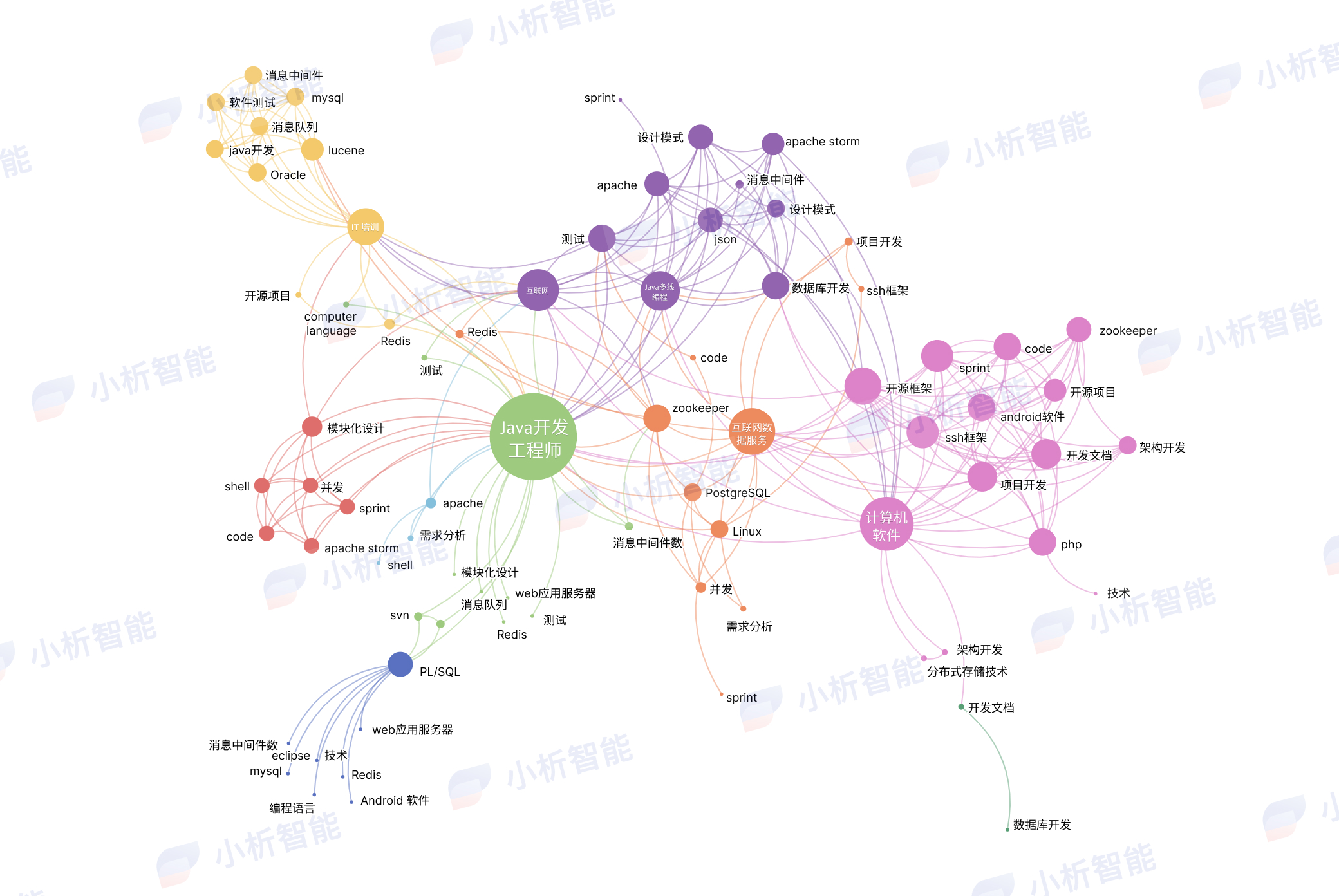
步骤二:通过Deepwalk和LINE模型形成embedding。利用Deepwalk生成不同的文本序列,使用skip-gram进行模型的训练,通过LINE则可以利用不同实体的共现次数形成模型的输入。
步骤三:模型的训练。不同实体出现的次数不一样,这对模型的训练有所影响。比如,如果专业名词在职位介绍中很少出现,将导致数据的不平衡。此时我们可以统计不同实体之间的TF-IDF、NPMI作为实体间的权重,从而表示不同实体之间关系的强弱程度,再进行模型的训练。
以上内容主要讲解了图嵌入的理论知识及其在人岗匹配方面的具体实践应用。除了极大促进人力资源行业发展以外,图嵌入还在很多领域取得相当成就,我们期待图嵌入能在更多领域、更深层次发挥更重要的作用。
参考文献:
1Perozzi B, Al-Rfou R, Skiena S. DeepWalk: Online Learning of SocialRepresentationsJ. arXiv preprint arXiv:1403.6652, 2014.
2Tang J, Qu M, Wang M, et al. Line: Large-scale information networkembeddingC//Proceedings of the 24th international conference on world wideweb. International World Wide Web Conferences Steering Committee, 2015:1067-1077.
3Grover A, Leskovec J. node2vec: Scalable feature learning fornetworksC//Proceedings of the 22nd ACM SIGKDD international conference onKnowledge discovery and data mining. ACM, 2016: 855-864.
4Wang D, Cui P, Zhu W, et al. Structural Deep Network EmbeddingC. knowledgediscovery and data mining, 2016: 1225-1234.
5Wu, L., Fisch, A., Chopra, S., Adams, K., Bordes, A., & Weston, J. (2017).StarSpace: Embed All The Things! arXiv preprint arXiv:1709.03856